1.A brief introduction to MLOps
A) Why MLOps
In very general terms, MLOps is the emerging practice of industrialising the production of Machine Learning (ML) models.
The production of a Machine Learning model is a highly hand-crafted process, especially when the volume of data is low. A Data Scientist’s working method generally consists of:
- Retrieving the data they need from their workstation
- Testing models on a Notebook
- Saving performance indicators to an Excel file
- Sharing the model with developers and DevOps so that they can put it into production
- Checking whether the production model behaves as expected via database queries
This whole mechanism can work if you work alone on your project and hope you never encounter any problems; but as soon as you have to work in a team and manage hundreds of algorithms, or the Data Scientist leaves the company or their workstation stops working, this mechanism quickly reaches its limits.
Here are some questions that may then arise:
- What is the latest version of the data to be used?
- What happened to the data that we spent so much time labelling?
- Have we already tested this or that algorithm? If so, how? With what results?
- Which Notebook was used to generate the model? Is it structured to be at least basically readable and maintainable?
- How do I know whether the model is working properly in production?
Well-defined processes can alleviate some of the aforementioned problems, but tools can also facilitate the daily life of data scientists today.

B) MLOPS at Twister
At Twister, Davidson’s IT department, we are working on various Machine Learning projects, including:
- A chatbot available on the homepage of the Davidson website https://www.davidson.fr/
- A recommendation engine that displays a personalised news feed on our Intranet
Until now, we have not used a tool dedicated to MLOps, which is why we have decided to carry out an opportunity study aimed at:
- Identifying what has already been tested, how, and with what results, so that it is easy to share what has been done and facilitate collaboration between Data Scientists
- Being able to replay past experiences, which is very useful in cases where you want to start again from a project or a previous test so that you have a baseline and not waste time trying to reproduce it
- Storing templates that are too large for Git (the limit is 100Mb, and language-processing or image-processing templates can easily exceed this size)
- Automating model re-training
We therefore decided to carry out a Proof Of Concept based solely on open-source technologies to industrialise our Data Science projects.
Note: We have not discussed the deployment part, because at Twister this part is already automated using Gitlab-CI/CD and OpenShift.
2. MLOps solutions
There are an increasing number of solutions, and it is not necessarily easy to choose between them. To appreciate the issue, simply visit https://landscape.lfai.foundation/
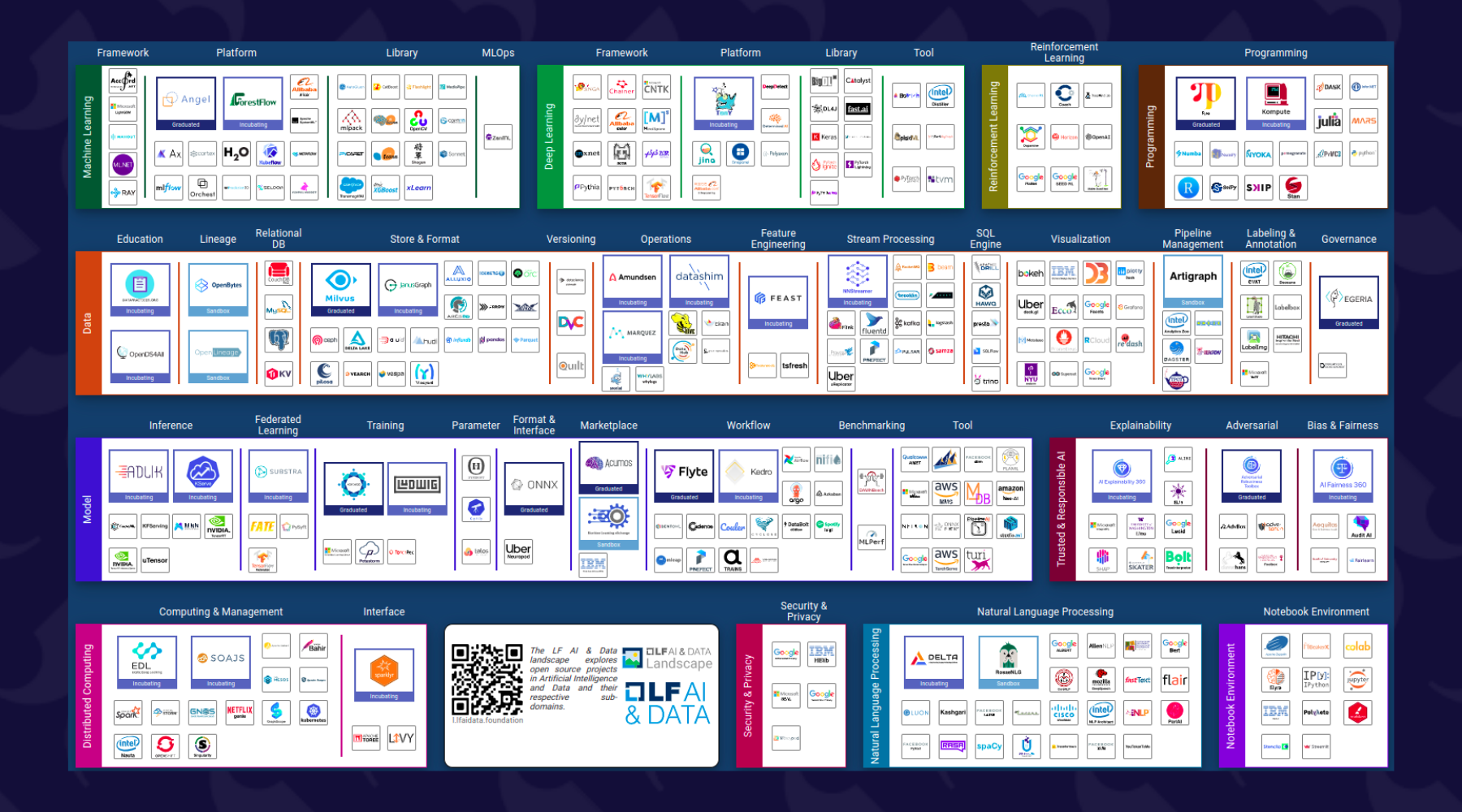
Some solutions cover several needs; others focus on a specific topic.
After an initial analysis of open-source projects, we opted to test the following tools:
- More general tools: MLflow, Metaflow and Kubeflow
- Specific tools for pipeline and workflow management: Airflow and Prefect
- Specific tools for data versioning: Pachyderm and DVC
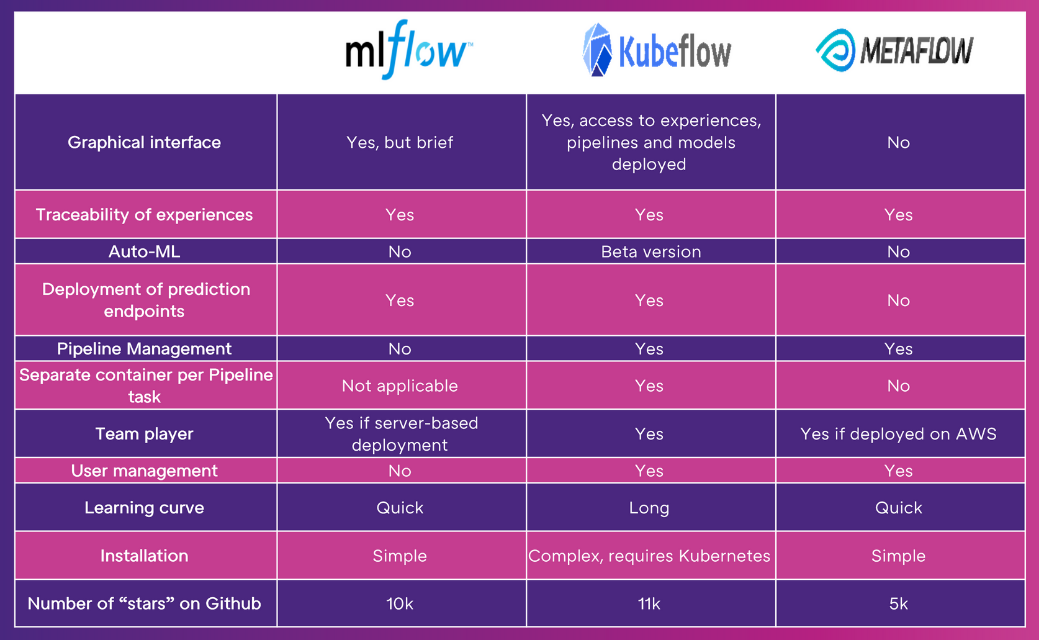
A) MLflow & Kubeflow & Metaflow
MLflow is a platform developed by Databricks, enabling the management of a large part of the life cycle of a machine learning project.
It offers various different modules:
- A module for tracking experiments
- A module for structuring the code of your project
- A registry of models
- A module for deploying your models
Kubeflow is a MLOps platform developed by Google based on a Kubernetes architecture. It mainly provides the ability to:
- Manage machine learning pipelines
- Store each of the artefacts of the output from tasks to enable experience tracking
- Deploy its models
Lastly, Metaflow is a solution developed by Netflix that provides a means of structuring your code into pipelines and tracking your experiments.
Below is a table comparing these three solutions:
B) Airflow & Prefect
These are 3 tools that allow you to manage pipelines, whether Machine Learning is used or not.
The best known is Airflow, which is widely used in organisations that need to manage many pipelines. The graphical interface is clear, it is possible to view the pipelines, restart failed tasks, plan them, etc. However, it is resource-intensive to deploy (it requires a server for the web interface and a server for the scheduler), and the pipeline development mechanism is not intuitive.
Prefect was created by one of the founders of Airflow whose aim was to simplify the system. Pipeline creation is indeed very easy, simply requiring installation of the Python package. It is also possible to deploy a server to trace pipeline executions and a graphical interface. Note that there is also an enterprise version with additional features such as user management.
C) Pachyderm & DVC
These are tools for versioning data and for structuring your code in the form of pipelines.
Pachyderm is very powerful because it stores only the differences between two versions of the same dataset. If a change is made to the dataset, the pipeline is automatically restarted. Another interesting point is that if a task in the pipeline is modified, only that task and the following ones will be re-run. There is also a graphical interface but this has been a paid extra since 2018.
DVC also allows versioning of large datasets. Its strong point is its simplicity of use: DVC uses Git syntax to version datasets and retrieve them. The downside is that for each DVC version, it stores the entire dataset, rather than just the differences.
3. MLOps solutions that apply to us
Our Data Science team consists of a few people, and we work on a limited number of projects. We are therefore primarily looking for a solution that is easy to implement, simple to operate, and has a quick learning curve. This last point is of key importance because the team is constantly evolving (interns, inter-contracts, etc.). The community around the projects, their activity, and the fact that they are not paid-for products in the medium term were also factors that were taken into account.
We then opted for the following stack:
- MLflow for experience tracking and Model Registry
- DVC for data versioning
- Prefect for pipeline management
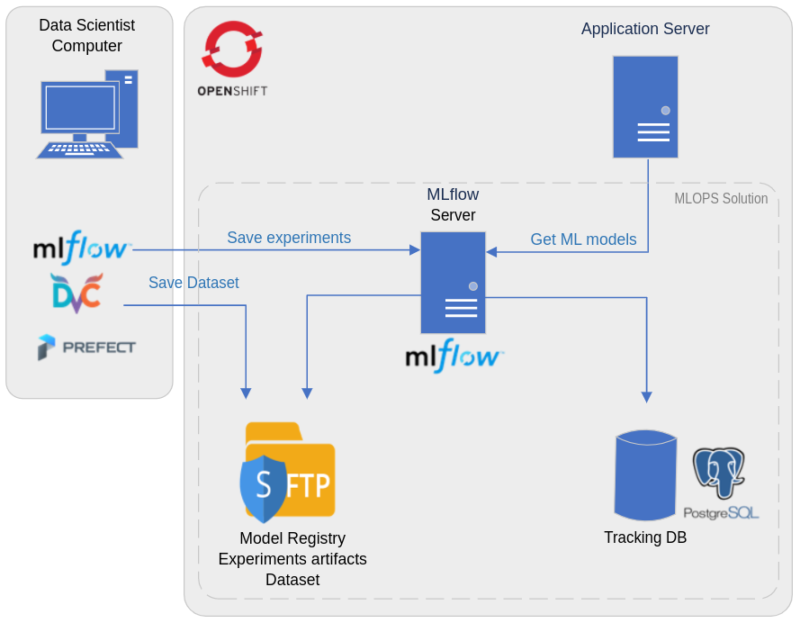
A) Architecture
From a technical architecture point of view, all the containers required for the solution are managed under OpenShift, with:
- A container for the MLflow server
- A container for the PostgreSQL database, which is used to store metrics and parameters for each experiment
- An SFTP container for storing experimental artefacts (such as images related to experimental results), models and datasets
B) Working methodology
The Data Scientist working methodology was reviewed to make the most of the functionalities offered by these tools.
The central element to the new methodology is the Git commit: this must be referenced for each experiment, so it is very easy to find the code that produced it. In addition, thanks to DVC, a small file referencing the data used is also added to Git. This allows the Data Scientist to find the data quickly and easily.
Step 1 – initiating the project
When starting from an existing project, the Data Scientist simply needs to run the following two commands to retrieve everything necessary:
$ git clone projet
$ dvc pull
A Data Scientist wishing to start from a previous test simply needs to obtain the appropriate commit number from MLflow, and run the following commands:
$ git checkout -b new_branch commit_number
$ dvc pull
This provides the Data Scientist with the code and the data to reproduce the baseline. The versions of the packages used are also important, and these are stored on MLflow.
Etape 2 – Conducting new tests
The Data Scientist can then carry out new experiments.
- If the modification concerns code (feature generation, new model, new way of splitting data), then this modification must be committed before starting the training. It is also possible to perform automatic commits to ease the process by using the GitPython package
- If the modification concerns model parameters, which are tracked by MLflow, then there is no need to make a commit.
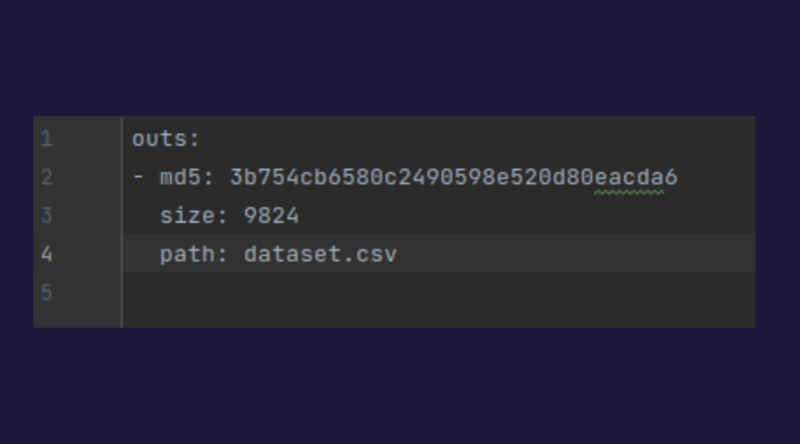
- If the modification relates to the dataset, the Data Scientist simply needs to run the dvc add dataset command
This generates a small file with the .dvc suffix, an example of which is shown here and requires a commit:
In addition, the dataset is automatically uploaded to the SFTP server.
Etape 3 – View results on MLFlow
The results are visible on MLflow and can be compared with previously-obtained results.
Below is the MLflow home screen, providing access to all the experiments being conducted.
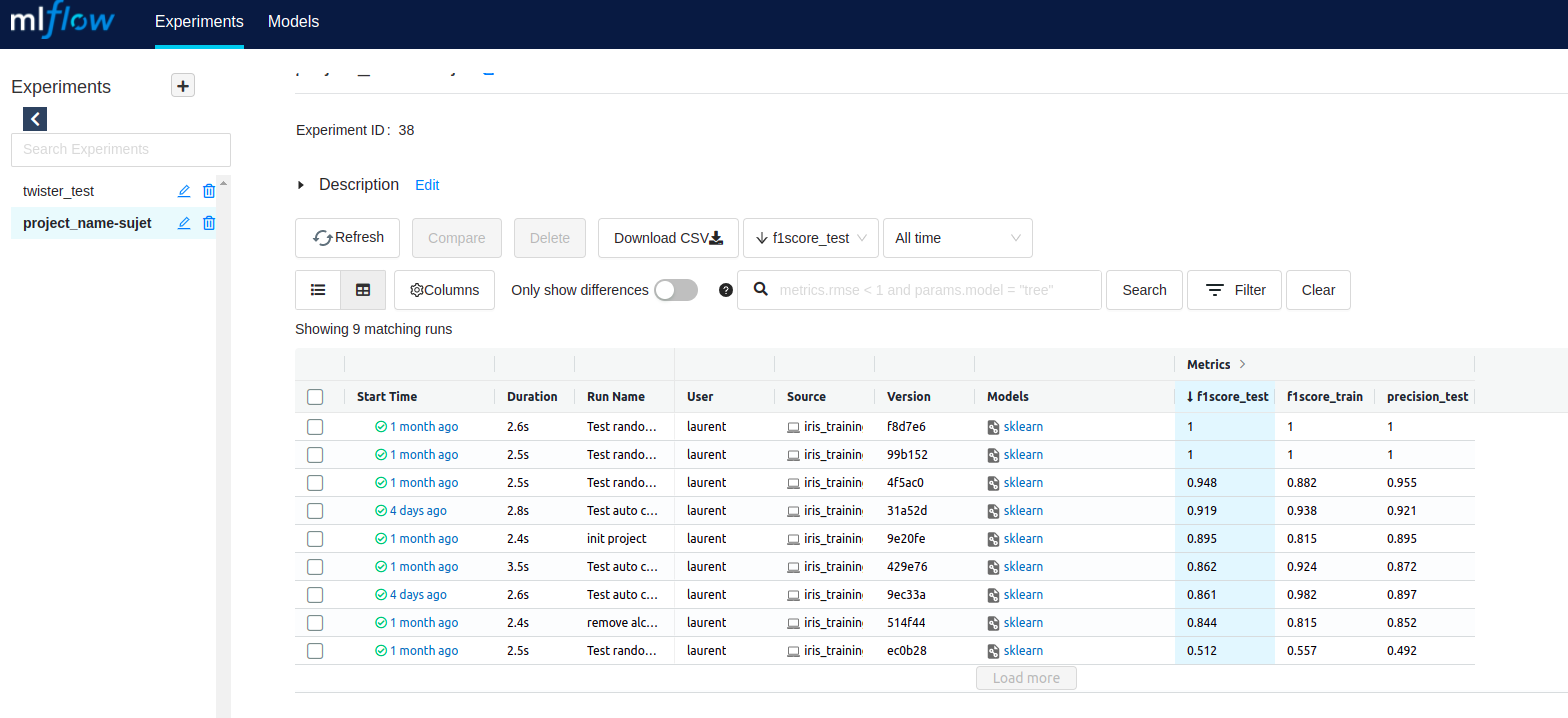
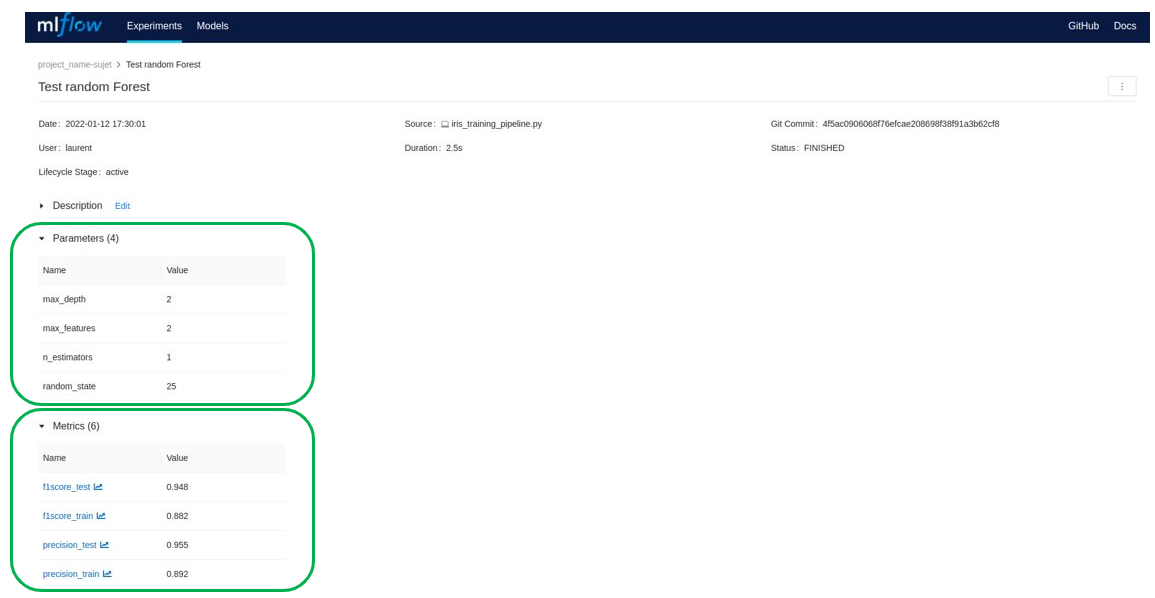
It is possible to consult the details of an experiment: the parameters, the results, the python packages used, etc.
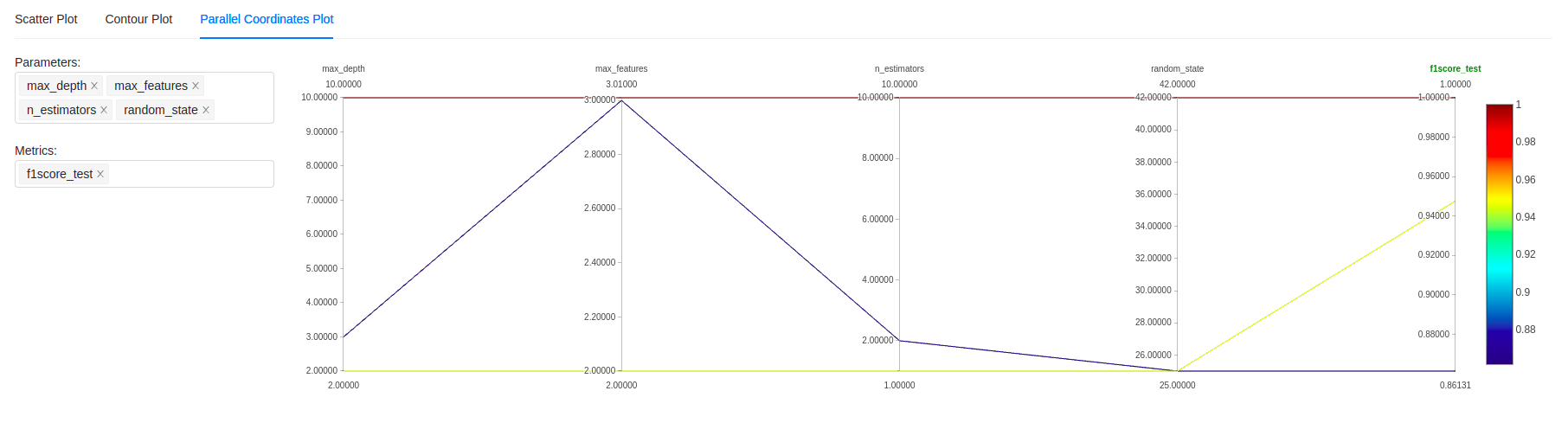
It is also possible to compare experiments at a more granular level using different types of graphs, including the classic “parallel coordinate plot” shown below:
Etape 4 – generate the production model
If the tests have been successful, the production model needs to be generated by committing the necessary code changes and then tracing the final result.
The model must then be registered in the Model Registry via MLflow:
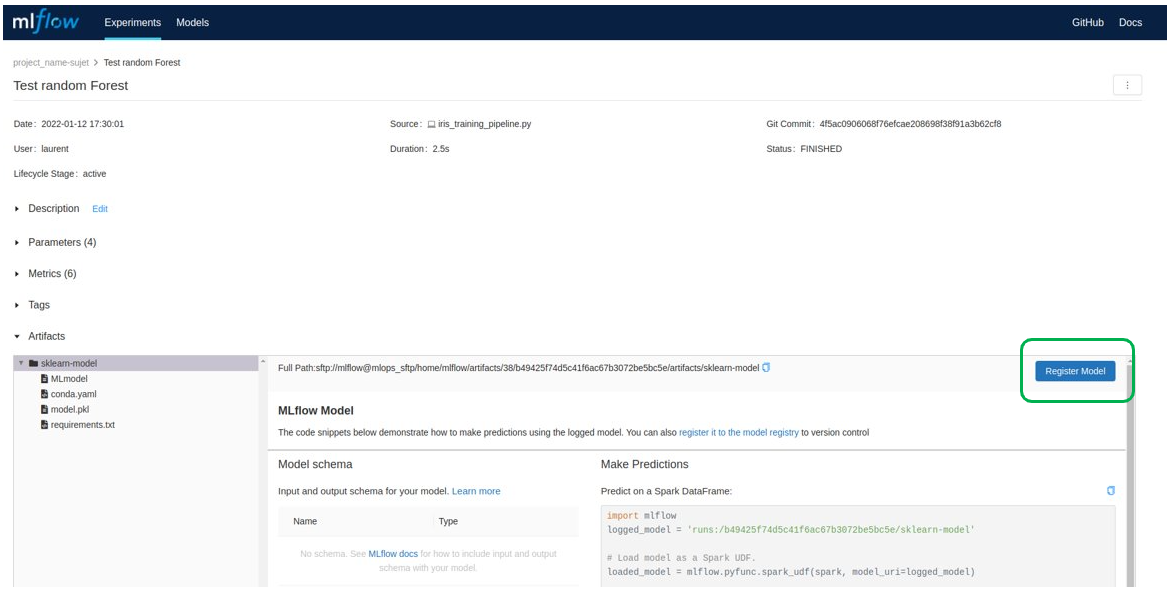
It can then be loaded into the code using the MLflow API. The model and the code required to run it must then be integrated into the production code.
C) Spotlight on the useof news packages
1.MLFlow
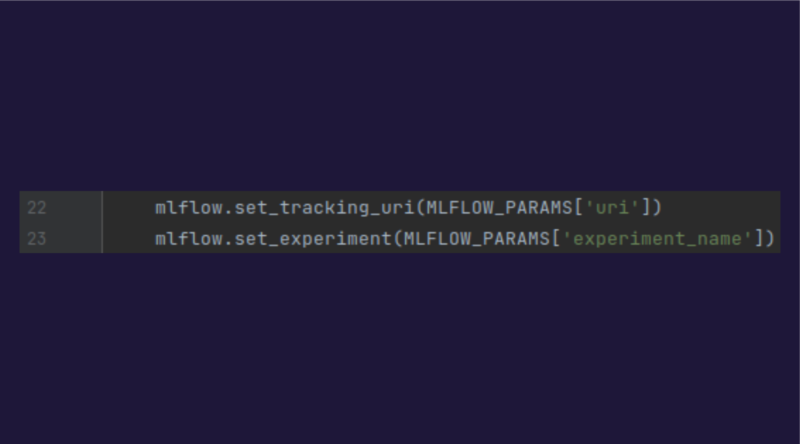
To use MLflow, the MLflow environment must be initialised by specifying the URI for the MLflow server and the name of the experiment:
You can then easily track what you want by using the appropriate methods:
- log_params
- log_metrics
- sklearn.log_model
It is therefore extremely easy to track anything you want.
2.Prefect
The use of Prefect in our situation mainly allows us to structure the code and make it easier to perform maintenance and model re-training.
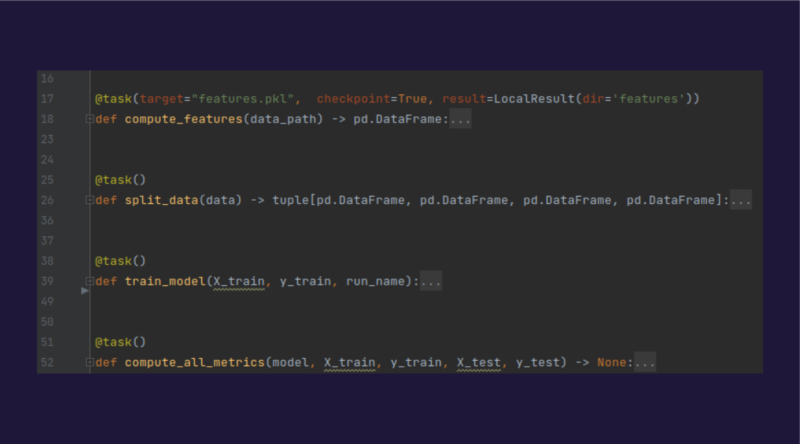
Each training session is broken down into tasks – each corresponding to a function – and together they form a pipeline.
To create a task, simply decorate the function you want via the “@task” decorator
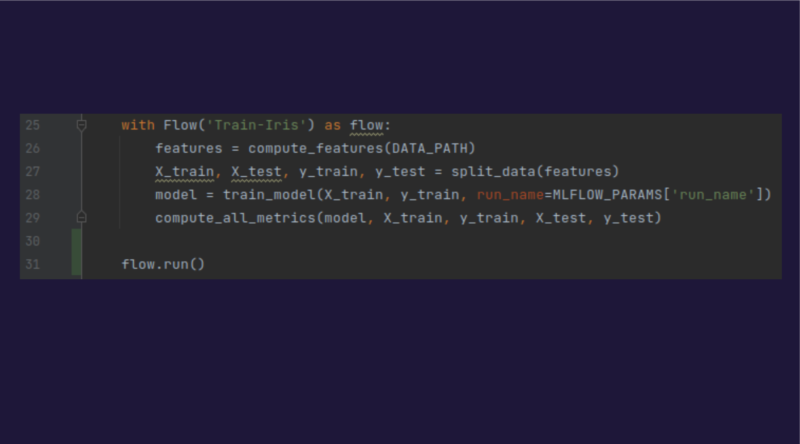
To create the pipeline, all you have to do is create a “context manager” that will chain the tasks together, and then execute it:
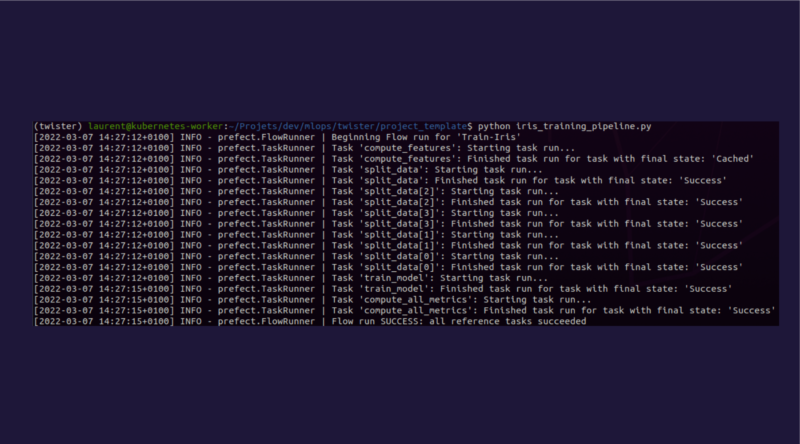
All that remains is to run the corresponding Python script.
4. I. Comparison costs
It is worthwhile comparing the costs for the 3 scenarios without industrialisation with the solution we have planned, and using a Cloud solution.
1. Without industrialisation
In cases where there is no industrialisation, costs are mainly generated by the time wasted by the Data Scientists in their daily tasks:
- Manual entry of scores and training metadata
- Attempting to reproduce the project baseline or the latest results that match the model currently in production
- Testing algorithms that have already been tested before
- Manually managing datasets to save them in a shared and backed-up space
- Manually re-training models
It’s hard to estimate the number of days lost per year, as this depends on the context and the type of project… however, it is reasonable to assume that it amounts to a major waste of time that should instead have been devoted to tasks that add value: industry watch, model improvement, code improvement, etc.
2. With “in house” industrialisation
The costs associated with the implementation of the aforementioned in-house solution are spread over several items:
An initial cost covering:
- Setting up the technical architecture for the solution under OpenShift, which is estimated to take 3 days
- Adapting the code from existing projects, which is estimated to take 5 days per project (this can naturally vary from project to project)
Next, the operating costs corresponding to the administration and operation of the solution, which we estimate at 10 days per year, and the costs related to hosting and OpenShift, which we estimate at €1,500 per year.
3. With a Cloud solution
With a Cloud solution, there are (as before) costs associated with adapting the code from existing projects.
Then there are the monthly costs of Machine Learning tools, which vary from one provider to another; taking the example of Azure’s ML Studio, with 4 vCPUs and 16GB of RAM, this comes to $192 per month per Data Scientist, according to https://azure.microsoft.com/en-us/pricing/calculator/ (not including storage, network, etc.).
5.Conclusion
A Data Scientist’s favourite tool has long been the notebook, which – if used without discipline – can quickly become messy and cause technical debt to balloon.
MLOps tools help to provide structure to the work of the Data Scientist and ultimately make his/her life easier. While it is true that this requires an initial cost to migrate projects and set up the appropriate infrastructure, the potential gains behind it are significant: better tracking means better understanding, which means more streamlined models, not to mention the benefits in terms of project maintainability and teamwork.