What is MLOps in the cloud?
A data scientist’s day-to-day work may include training predictive machine learning or deep learning models. Sometimes this task is performed using an approach that’s somewhat cobbled together: tests carried out on a local workstation, results not shared, code not optimised, etc. In addition, a data scientist isn’t necessarily trained to deploy models in production.
This is why the three main cloud players (Amazon, Google and Microsoft) are now offering tools to make data scientists’ work easier. They’re called:
- SageMaker (Amazon)
- Vertex AI (Google)
- Azure Machine Learning Studio (Microsoft)
This article aims to present the main features offered by these three cloud giants. For more information on what MLOps is and its benefits, visit https://www.davidson.fr/blog/le-mlops-au-secours-du-data-scientist
NB: this article follows a study on industry standards conducted independently of the three vendors.
Data management
Datasets
A dataset is all of the data used to create a machine learning model. This includes both data used for training and data used to verify the model’s proper functioning.
Microsoft and Google offer an abstraction layer that allows you to create datasets from your data. The main advantage over directly using data stored in a csv file or a database is that you can easily version the training data.
Features store
In machine learning, features are the information that describes the data. For example, if you want to predict apartment prices, the features could be location, surface area, number of rooms, floor, etc. We can therefore have both numerical and textual features. Algorithms need numerical data in a certain format in order to train, meaning there is a whole “features engineering” phase in which the data scientist has to convert the initial features into features that the algorithm can use.
This is where feature stores come in, allowing the features built by the data scientist from the initial data to be stored directly. The advantages of a feature store are as follows:
- Pool the creation of features that can be used by the algorithms, thereby lightening the workload necessary for the features engineering phase
- Ensure that features are generated in the same way between the training phase and the prediction phase when the model is in production
Google and Amazon offer this feature store service directly integrated into their solution.
Microsoft offers it through its partner Databriks.
Data analysis & cleaning
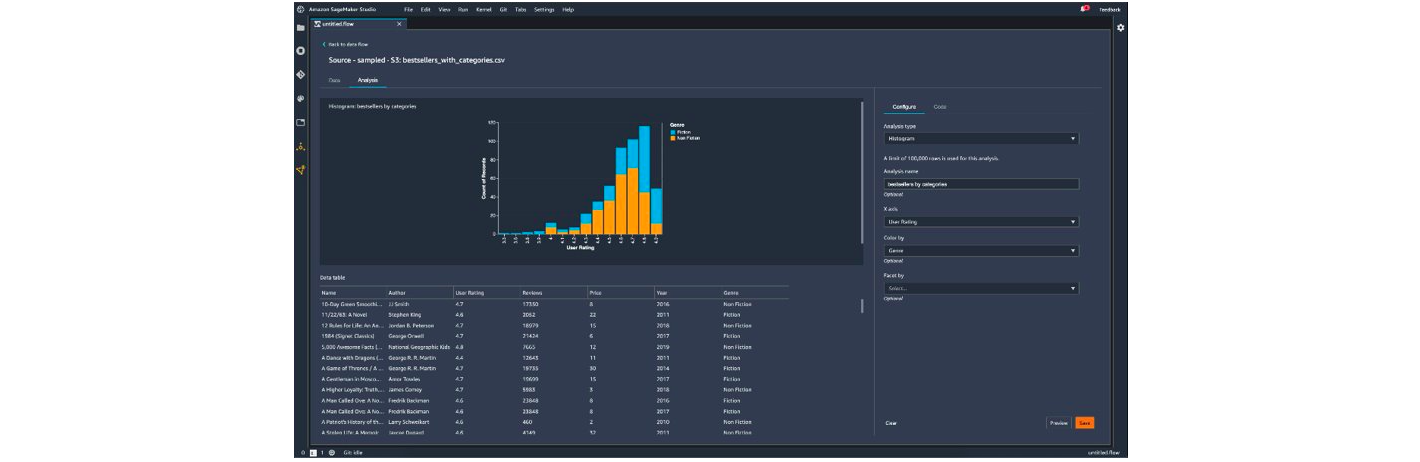
Data analysis and cleaning are long and tedious steps that data scientists have to undertake. This task is usually performed with code on a notebook.
Amazon offers a feature called “SageMaker Data Wrangler” that handles this task without code. Microsoft also offers it via the “Azure Machine Learning Designer”. The advantages are:
- Empower the business line to work with the data itself, since it has the most knowledge about the data
- Become more efficient
Below are captures from the Amazon and Microsoft studios allowing data cleansing without code:
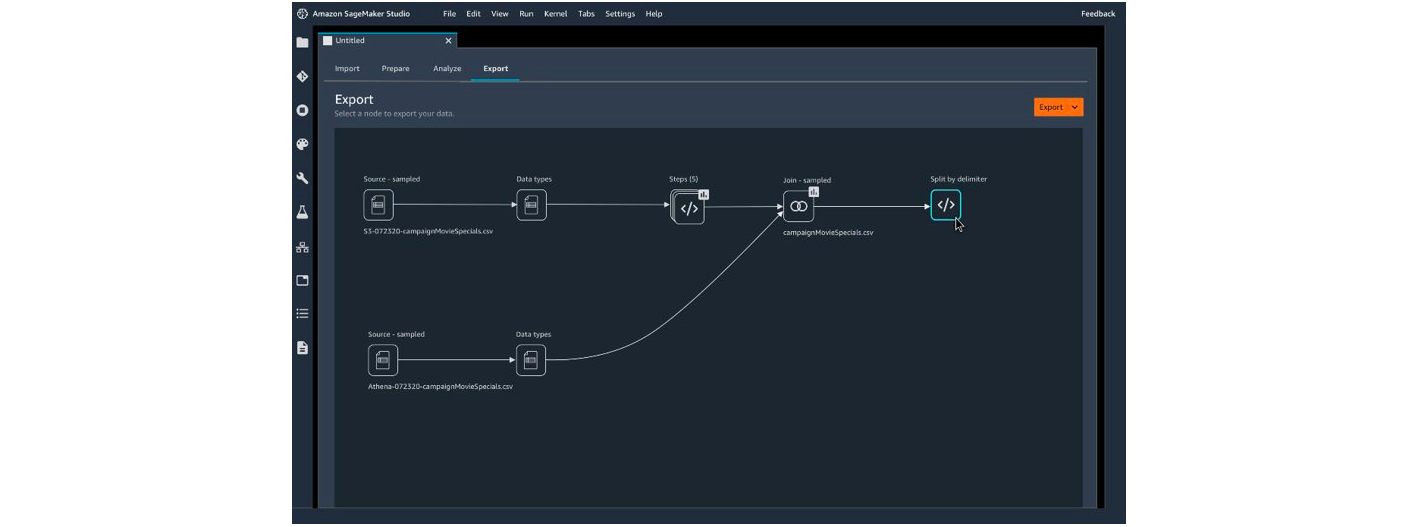
Figure – Amazon SageMaker Data Wrangler
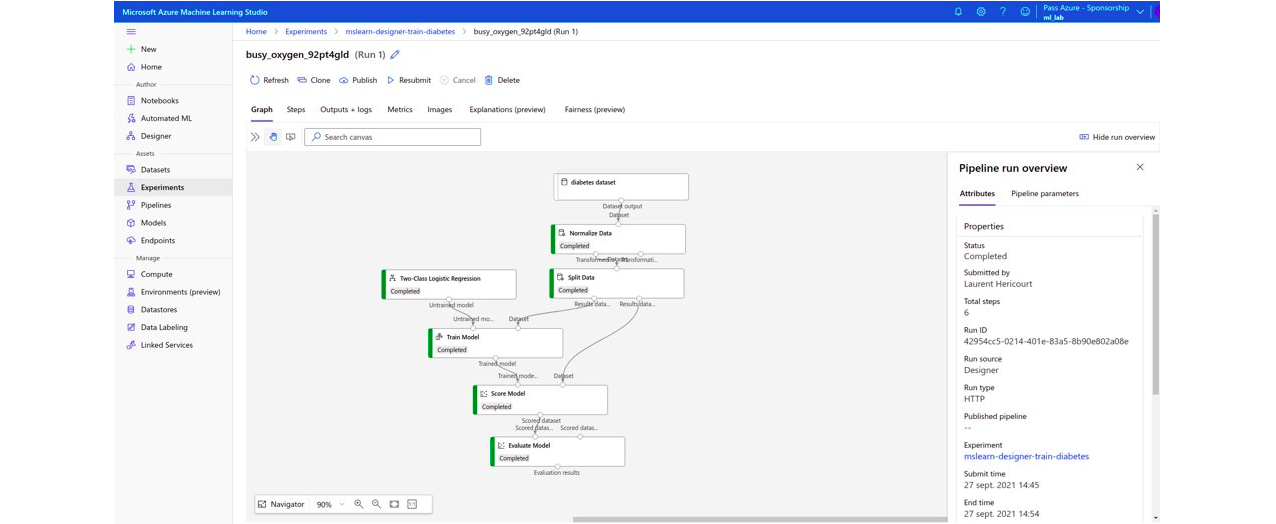
Figure – Microsoft Azure Machine Learning Designer
For the analysis part, Microsoft can display statistics on the data (missing values, minimum, maximum, etc.), while Amazon also lets you create visualisations (histograms, scatter plots, etc.).
Summary of the three data management solutions

Model training
Auto-ML
All three cloud solutions have an auto-ML feature, accessible from a graphical interface or via code.
AutoML involves automatically generating a machine learning algorithm. It is responsible for:
- Testing different types of feature engineering
- Testing different algorithms
- Selecting the best algorithm
This means that someone who doesn’t know anything about machine learning can create their own models independently: they just need to indicate the data to use, the column to use as a label and launch the training.
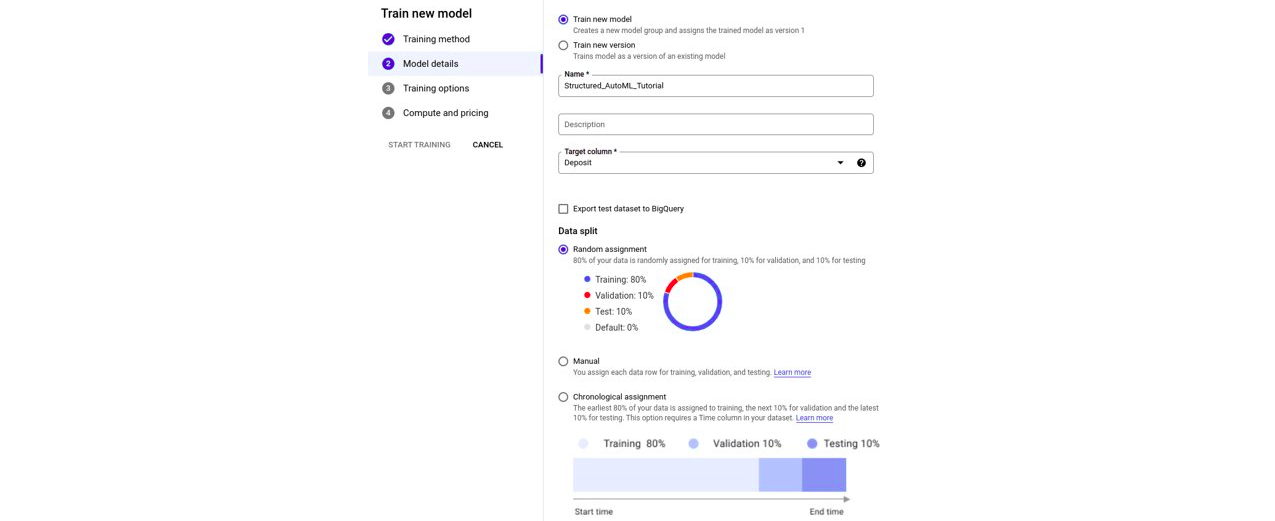
Microsoft Azure allows you to view the models tested and the conversions performed on the data automatically in the form of graphs. Note that for the uninitiated these graphs aren’t very meaningful.
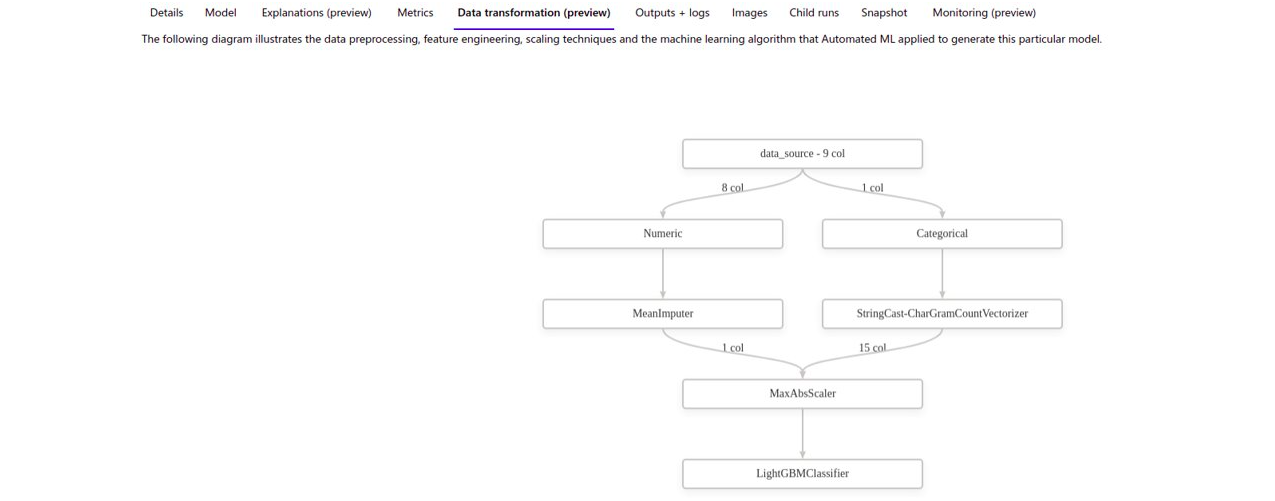
Meanwhile, Amazon Vertex doesn’t offer an explanation if the purely graphical solution is used (called SageMaker Canvas). However, if you use AutoML via code (a solution called SageMaker Autopilot), a notebook is generated describing in text form the tests performed:

For Google, the information on the tested models is available in logs in JSON format, which isn’t necessarily easy to read:
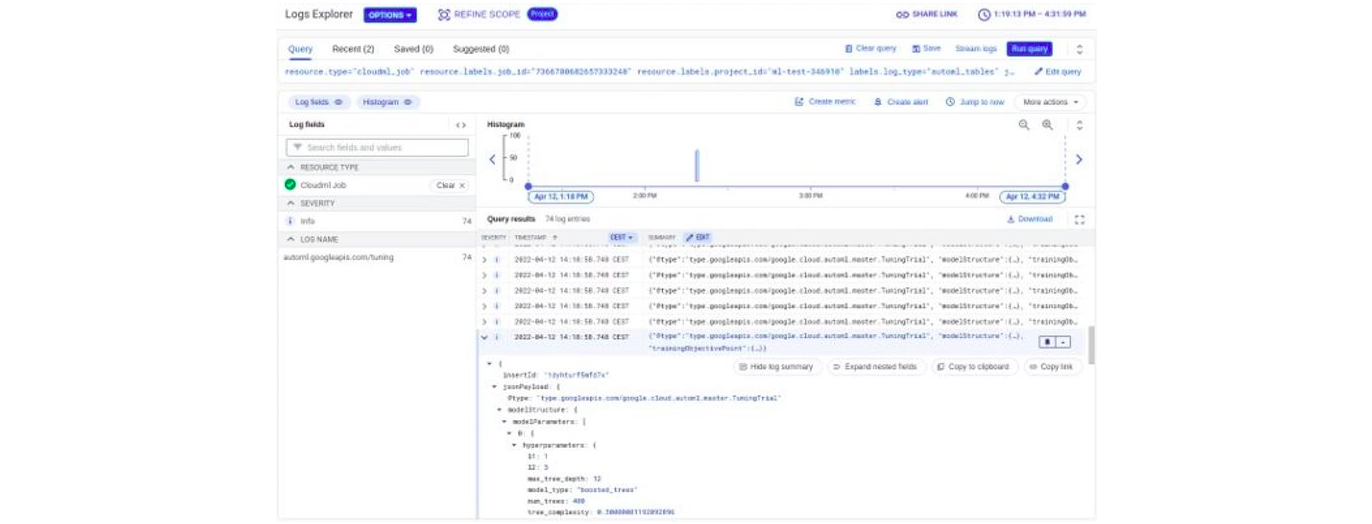
The last point to note is that Google’s solution seems to be a little light on feature engineering automation compared to its competitors.
Below is a comparative table of our opinion on these three AutoML solutions:

In conclusion, although the AutoML feature may seem magical, it isn’t without risk. It isn’t advisable to put models into production if you aren’t proficient in them. How can you debug if you don’t know how it works? How can you analyse it? On the other hand, this feature is very interesting as a first step for data scientists. With a few clicks or lines of code, they can get an initial overview of which models work best.
Training “manual” models
“Manual” means that you can train your own models without using AutoML.
The three solutions offer more or less the same thing, namely:
- A notebook environment for testing, data mining, small training sessions, etc.
- Libraries (Python, Node.js, etc.) to interact with the cloud environment (creation of datasets, models, endpoints, etc.)
- The ability to choose the type of machine instance on which to run the training. This last point this is where cloud solutions’ real power lies: in a few clicks or a few lines of code, you can run training on any type of machine (choose the number of CPUs, memory, number of GPUs)
- The ability to test your code locally rather than directly in the cloud, so you don’t have to start a cloud instance whenever you do any testing
- A registry model to store and version your models
In this “manual training” part, Microsoft provides the ability to generate models through the designer’s graphical interface, therefore without doing any code. Machine learning skills are required to use this feature. In addition, the designer isn’t very intuitive, so there is limited benefit.
However, Microsoft’s strength is the model comparison part, as the graphical interface is very clear and easy to use.
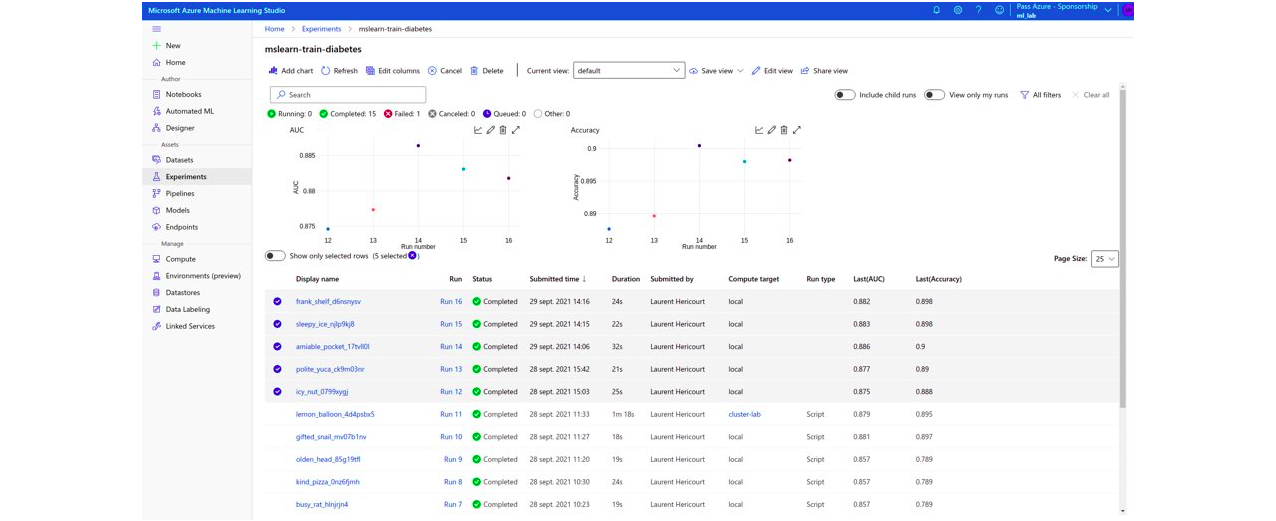
With Amazon’s solution you can also compare models, although less intuitively.
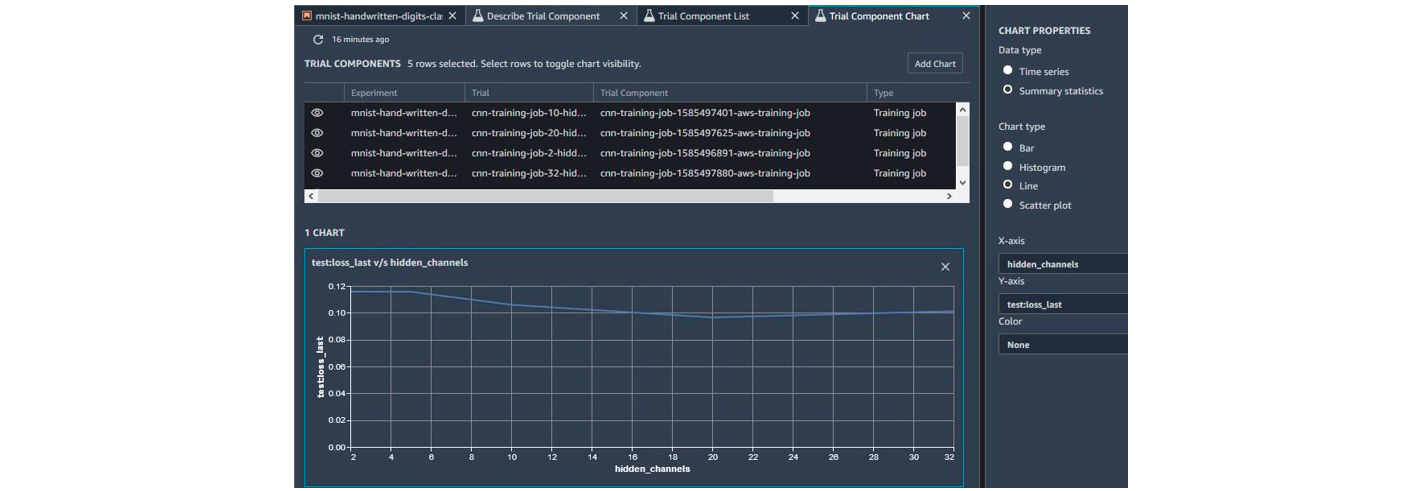
Amazon SageMaker Autopilot – Comparison of results
However, Amazon offers a whole list of indicators and rules to make it easier to debug a model.
With Google you can use TensorBoard. However, there’s no particular benefit in using the cloud version compared to the version that can be installed locally.
Below is a summary of the model training features.
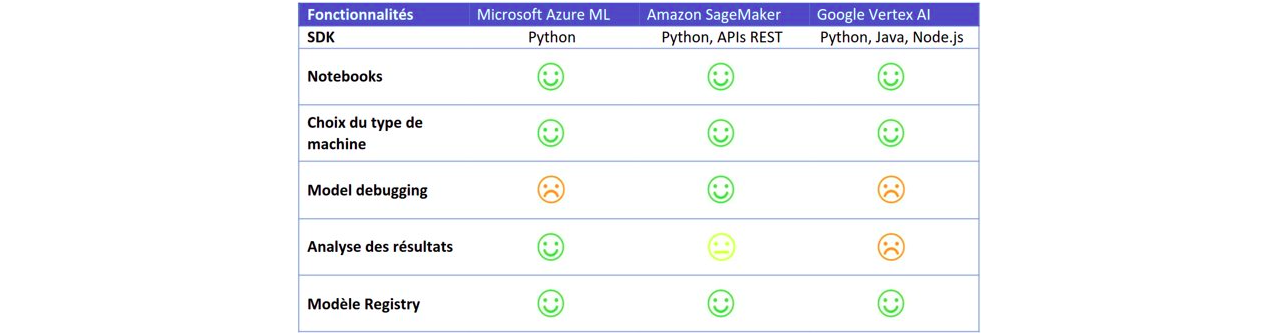
Ethical Artificial Intelligence
Ethical AI is about ensuring that the models deployed are respectful, transparent and fair. Going into more detail, this includes:
- Not reproducing societal biases (discrimination regarding a given criterion)
- Being able to understand why the algorithm made a particular decision
- Respecting individuals’ privacy
- Respecting individuals’ freedom
- Respecting the environment
Regarding the explainability aspect of the models, the three vendors propose the use of “SHAP values”. Microsoft offers LIME and PFI, while Google adds XRAI and Integrated Gradient.
Microsoft provides a very good graphical interface to compare the model’s behaviour for different types of population.
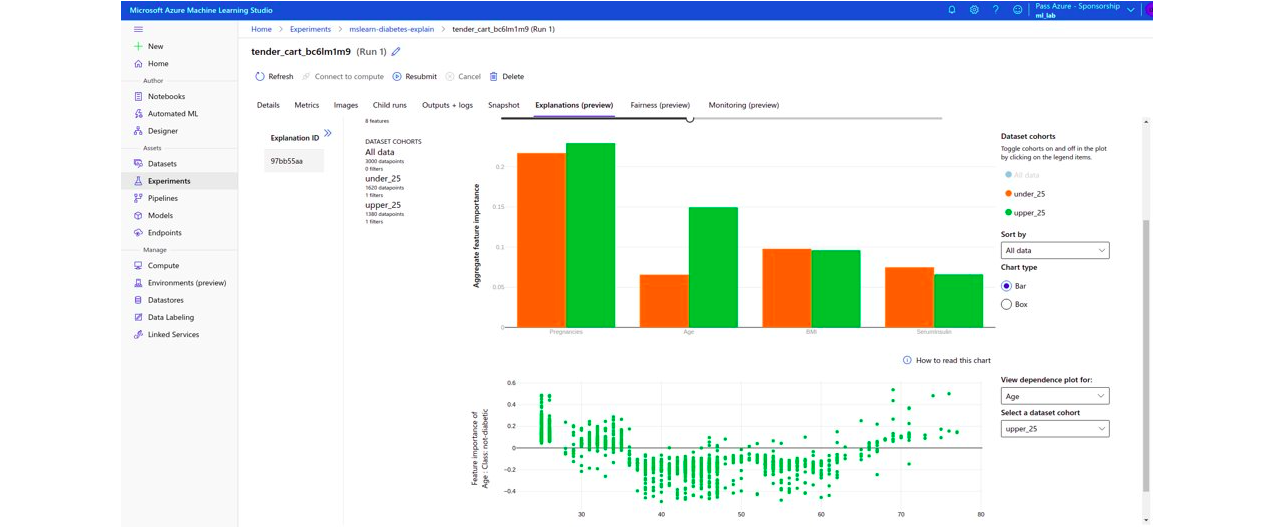
Amazon offers a basic interface, while Google doesn’t offer one.
Regarding “model impartiality”, Azure provides a few indicators (it uses the Fairlearn package), Amazon offers around 20, with a detailed explanation of each, and Google none.
Below is a summary of the ethical AI features.

Deployment of models
Once the model has been trained, the solutions offer to deploy it in a few clicks or via a few lines of code. Deploying a model means providing an endpoint (a REST API) that takes as input the data on which to make the prediction, and returns the model prediction.
In deployment you can add processing upstream or downstream of the prediction via specific code.
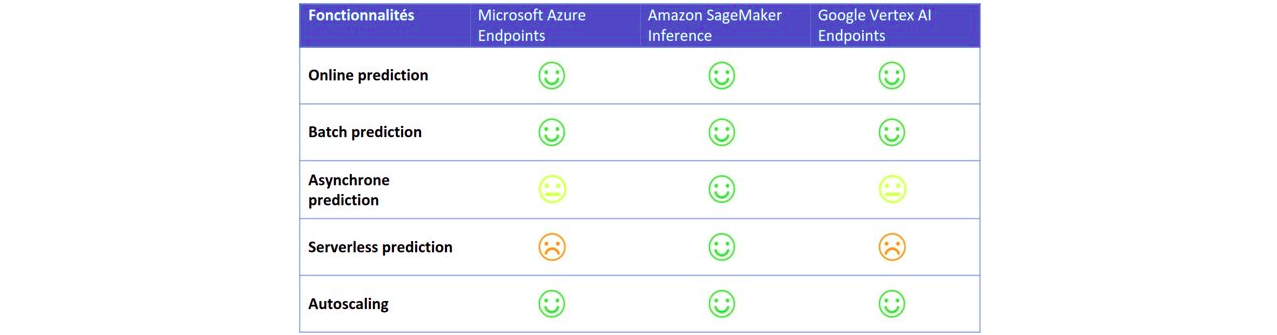
All three cloud providers offer predictions called:
- “Online”: predictions are made in real time (synchronous queries); predictions can be run on a single data item or several
- “Batch”: predictions are made asynchronously, then the results are saved but not directly returned to the user; this is generally used when predictions are being made on large volumes of data
Amazon SageMaker offers two other types of deployment:
- “Asynchronous predictions”: This type of prediction can be used when you want to make predictions in near real time but don’t want to block the user during the prediction. Compared to batch prediction, the user (or client) can be automatically notified and the result automatically retrieved.
- “Serverless predictions”: this type of deployment makes it possible to completely offload the infrastructure sizing and scaling policy. The infrastructure is automatically sized according to the load at a given moment. The important point when using this type of deployment is that the service must tolerate cold starts, as the service isn’t available until the first instance starts up.
Monitoring of models in production
All three solutions store the predictions made by the models and the data that led to those predictions.
Microsoft uses the Azure Application Insights solution to store this information in logs. Queries can be run in these logs using the Kusto language (KQL). However, these logs aren’t easy to utilise; below is an example of what can be obtained:

With Google the predictions are stored in its BigQuery data warehouse. If you aren’t an expert in BigQuery queries, the results aren’t easy to utilise either.
Lastly, Amazon saves the predictions in files on S3.
All three solutions also offer a drift analysis feature, “drift” being the change in the distribution of data over time. It’s important to keep an eye on this because if the data changes, the model will no longer perform properly, meaning it will need to be retrained.
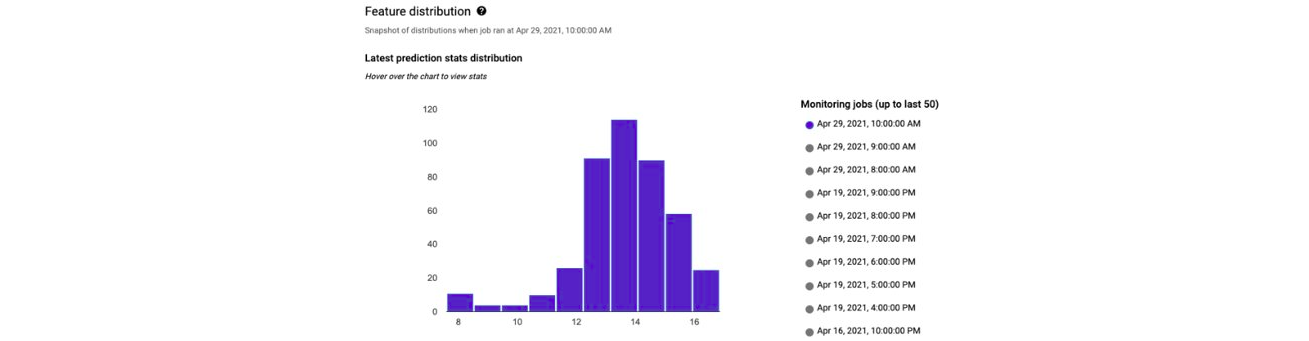
You can also send automatic alerts if there are significant changes in distributions, i.e. drift.
One point for consideration is that in some cases the calculation of the drift indicators isn’t explained, so it’s difficult to define a threshold to automate the alerts.

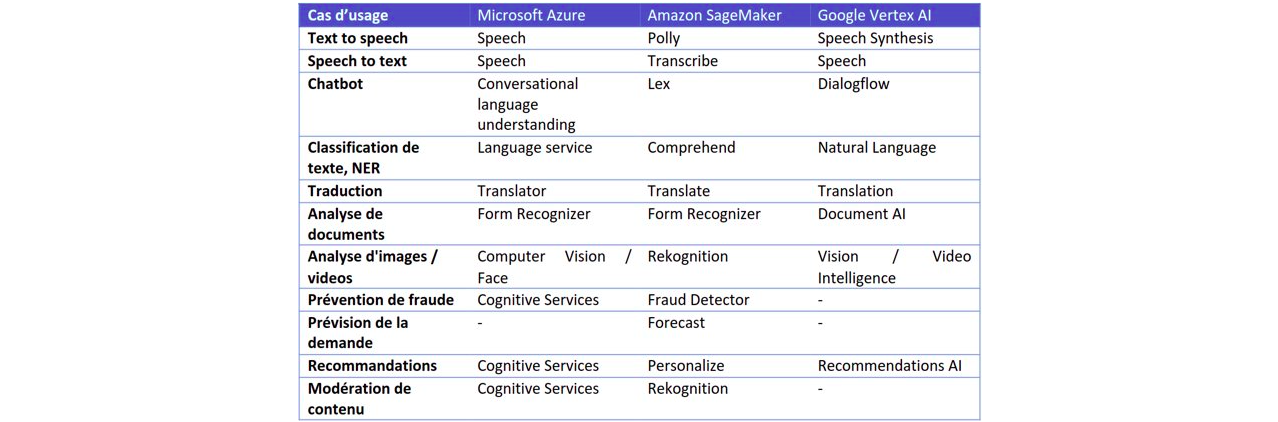
Specific AI services
The three cloud providers supply Artificial Intelligence solutions for specific use cases. These are use cases that are often complex to develop yourself (image classification, chatbot, etc.).
You simply give the service your own labelled data, then an algorithm is automatically trained on it and, if the results are convincing, it can be deployed.
The table below lists the different use cases covered by each vendor, including the name of the solution.
Pricing information
Prices are broken down into several items: the instances on which studios/notebooks run, the instances on which models are trained, the instances on which models are deployed, the storage, the network, the load balancers, etc.
This means it’s very complicated to estimate the cost of using these solutions for your own needs. In the table below we compare the price of the calculation instances, which are the main cost items; the prices are for the Eastern region of the US:

We can see that in terms of calculation instances the prices are quite similar.
Summary and conclusion
The three cloud providers offer roughly similar services. Azure’s strength is its easy-to-use studio, while Amazon’s strength is its varied deployment options. From our point of view, Google has no strong differentiator.
These tools provide real added value for data scientists thanks to:
- Auto-ML, which allows data scientists to quickly get an initial estimate of the performance the algorithm will be able to achieve
- The studio, where the history of trials conducted can be displayed and a record kept of the work done
- Deployment features that allow data scientists to deploy their models themselves
Note: As there aren’t many differentiators, we recommend choosing a solution based on the ecosystem available to each party at a given time, as the use of machine learning alone doesn’t justify switching cloud provider.
Laurent HERICOURT – Lead Data Scientist